
Jort van Wijk1, Mario Alvarez Grima2, Tanaka Moyo3
1 IQIP, Sliedrecht, Nederland
2 Royal IHC, Kinderdijk, Nederland
3 IQIP, Sliedrecht, Nederland
ABSTRACT
Unexpected pile run in soft soils during windfarm installation, project delays due to hard soil strata and uncertainty about the need for drive-drill-drive operations. These examples show that hundred percent installation guarantee still is something for the future.
Early 2000, neuro-fuzzy modelling was introduced to the engineering geology community in The Netherlands, and today, a wealth of data on soil conditions and installation methods becomes available with every newly installed foundation. Large quantities of high-quality data can turn ‘artificial intelligence’ and in particular machine learning and deep learning algorithms into powerful tools. We want to put these tools to work for de-risking foundation installation projects.
Combination of advanced CPT interpolation, historical project data and real time feedback during installation enables risk quantification, optimization of the installation method and real time assistance to operators around the globe. Hundred percent installation guarantee is becoming reality.
KEYWORDS : Foundation installation, Driveability analysis, Project risk, Machine learning, Data driven services
Introduction
The history of supporting structures by pile foundations goes back centuries, and applications have extended from the terrestrial into the maritime domain. First with foundations for oil and gas field developments, currently even more visible with the development of offshore wind projects. All foundations serve a common purpose: to keep man-made structures fixed and firmly attached to the ground.
IQIP is specialized in foundation installation equipment (hydraulic impact hammers, followers, templates, gripper tools, noise mitigation screens and handling tools) for civil and coastal, oil and gas and offshore wind projects. In the last 20-years, IQIP’s Hydrohammers have installed roughly 80% of the offshore wind farms (OWF) in the North Sea alone, and globally IQIP is involved in more than half of the offshore wind developments. As such IQIP has acquired significant experience in foundation installation projects and has acquired the related installation data.
Specifically for OWF developments, project risks comprise pile run, refusal and exceeding noise limits during installation. Risks arise from a combination of soil conditions, human action and project legislation and mitigation should address all these aspects.
One of the ways of understanding and mitigating project risk is a comprehensive driveability analysis, which considers critical aspects of the soil, pile and hammer in order to ensure the piles can be driven safely to design depth. Traditionally these are focused on best estimate and upper bound conditions, however we see an increased attention for mitigating risk concerning ‘soft’ driving conditions as well. These are given by noise limitations during piling and by risks of pile run. Here the lower operational limit of the hammers comes into play: how gently can one drive the pile?
IQIP believes that installation risk mitigation should be an integral part of the project and is becoming essential as project capital risks increase. By combining our extensive project track record with machine learning technology and web-based services, we aim to reduce foundation installation risks by the best possible informed decision making during different project stages.
PROJECTS, DATA and LEARNING
Digital services require transformation from a project driven infrastructure to a data-driven infrastructure. As technology advances customers are getting more accustomed to receiving digital services via mobile and desktop applications. IQIP aims for additional value delivery components as a web app and the IQIP C-66 & C-36 hammer control systems, which will allow customers to have up-to-date input for their projects at all stages.
This transformation requires connecting data coming from all project stages into a data hub. Unlike a structured relational database, a data warehouse or data lake, the data hub is a collection of data from multiple sources organized for distribution, sharing, and often sub-setting and sharing.
In the IQIP data hub, historic datasets of offshore pile driving operations are stored. A typical dataset contains over 300 different parameters (e.g. site conditions, soil data, system specifications, pile data, driveability calculations and the actual driving records), which is complemented with asset data from the ERP system, IoT sensors and third-party data as AIS vessel movement and C4 OWF project data. Using custom scripts with OCR (optical character recognition) algorithms, project specific data is extracted from these various sources, transformed and loaded into the data hub.
The value of this data can be partially harvested by conducting traditional back-analyses, in which predictive models are improved, e.g. the conversion from soil data (CPT, borehole logs) to the soil resistance experienced by the pile (SRD model), which then become input to new driveability analyses. The well-known Alm and Hamre SRD model (Alm and Hamre, 2002) itself is based on a best fit of >200 jacket piles installed in the North Sea. This step by step learning process relies on intermediate physical models of which the model parameters are calibrated with the field data that is streamed to the data hub. Keeping track of which parameter set works well under which circumstances remains a manual and laborious task.
Although valuable, back analyses are only one of the ways of creating value with data. More advanced methods can be, and should be, employed to harvest the full potential of data. This is where machine learning algorithms come into play.
Artificial Intelligence (AI) in Geotechnical Engineering
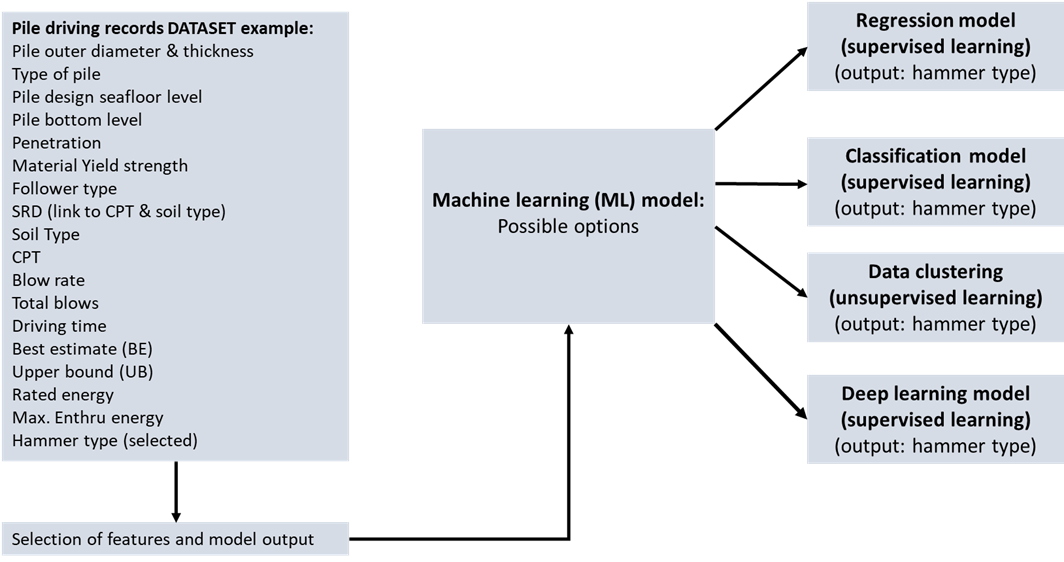
AI is dedicated to making machines smart. Machine learning (ML) is a subfield of AI and is focused on algorithms and codes in order to make predictions. ML is considered a data-driven approach and allows computers to learn from existing data without being explicitly programmed. In general, ML can be divided in supervised and unsupervised learning. In the case of supervised learning the problem to be solved consists of known inputs and outputs. The algorithm learns the relationship between them using a training dataset until the model achieves a desired level of accuracy. This type of learning is commonly used for regression and classification problems. When using unsupervised learning, the algorithm searches for patterns in the data without a teacher, i.e. the output is not explicitly defined. This method is used for data clustering based on similar features. Unsupervised learning can help to recognize hidden patterns that are typical for large and multivariable datasets.
When using supervised ML there are basically two approaches: classification and regression. In classification, the algorithm assigns labels to data based on the predefined features. Regression algorithms on the other hand try to find a relationship between variables and predict unknown dependent variables based on known data.
Building an ML model comprises a number of steps from problem framing to model predictions, in which the data and modelling options are studied using multiple statistical methods. The quality of the predictions is directly related to the quality of the database, and predictions outside of the data range are prone to large inaccuracies. Establishing quality criteria for the database and establishing the confidence intervals of the model are very important.
ML, and more specifically neural networks and deep learning (subdomains of ML) have been used effectively in geotechnical engineering applications, where uncertainty is inheritance to the problem (Alvarez Grima, 2000). Geotechnical design parameters are not always directly measured from laboratory and in-situ tests, rather often estimated from empirical correlations. One important characteristic of ML is that it can deal with multivariable and non-linear relationships in a very robust manner, excelling in both model accuracy and skill when compared to traditional methods such as statistics. In this way, ML can contribute to de-risking projects by increasing accuracy and by including all past project experience into every new project without the need for intermediate physical models and back-analysis on a case-to-case basis.
Applications of ML to foundation installation
For every installed foundation, a driveability calculation is made. Current practice requires modelling a 1D wave propagating through the hammer-pile-soil system. The hammer-impact (1D collision) introduces a stress wave in the pile. The deformation of the pile by the stress waves is coupled to the deformation and associated resisting forces of the soil acting on the pile. Simulating successive blows (which can be done for various hammer settings) provides a calculation of amongst others the driving time, the total blowcount and the stresses occurring in the pile. Driveability analyses rely on engineering data, experience and expert opinion, and are consequently subject to many uncertainties.
An important step in driveability calculations is selection of a hammer that is able to drive the pile to final penetration under predefined constraints of minimum and maximum blowcount and maximum pile stresses. The selection is based on a single soil dataset, using empirical resistance models of which the parameters are based on best engineering judgement of the engineer, and each variation in hammer specification or soil conditions requires the entire simulation to be run again. The accuracy of the calculation will only show when the pile is actually driven. This method is potentially precise, but cumbersome, and lacks incorporation of earlier experience other than improved SRD models by regular back-analysis, while incorporating earlier experience in every new calculation is key in reducing project risks.
Introducing ML to driveability analyses has clear benefits in both early stage design and final project execution. In early stage design exercises a large number of pile-soil combinations is involved, the exact pile geometry is not determined yet, soil conditions are only roughly known and potentially highly variable and where different driving strategies are required with an eye on noise emission. Since regular driveability calculations are laborious, one would normally select a typical pile-soil combination at the risk of overlooking specific situations (e.g. a hard layer with refusal risk or too high noise emission). ML is particularly suited for multivariable non-linear relations between many parameters, and as such it can include the entire wind farm already in an early design stage rather than a single exemplary pile.
In the project execution phase, ML can assist in real-time piling procedures for every new pile to be installed, considering the driving records from all previous piles in the wind farm. Especially in the case of high pile run risks, specific piling procedures can significantly reduce the risk.
We have worked out two examples of ML in driveability analyses to illustrate its use. The first example is application of very straight-forward ML to hammer selection (Figure 1), using linear regression and clustering. We have selected a number of 36 regular driveability studies, conducted over the past 4 years by two engineers. The projects span the IQIP hammer portfolio S-70 to S-3000 and cover a wide variety of soil types and project locations, both on land and offshore. For selection of the relevant parameters, we conducted regression analysis on the advised hammer type (by energy rating, e.g. S-70 denotes a 70 kJ hammer) as preferred output, and the pile outer diameter, final penetration, pile foot area and the maximum value of the driving resistance SRD as potential inputs. This exercise has shown good correlations between hammer energy and pile outer diameter and maximum SRD value respectively. Clustering of hammer energy around pile diameter and SRD gives satisfactory results as well, allowing for the definition of applicable hammer energy ranges given OD and maximum SRD. See Figure 2 for details.
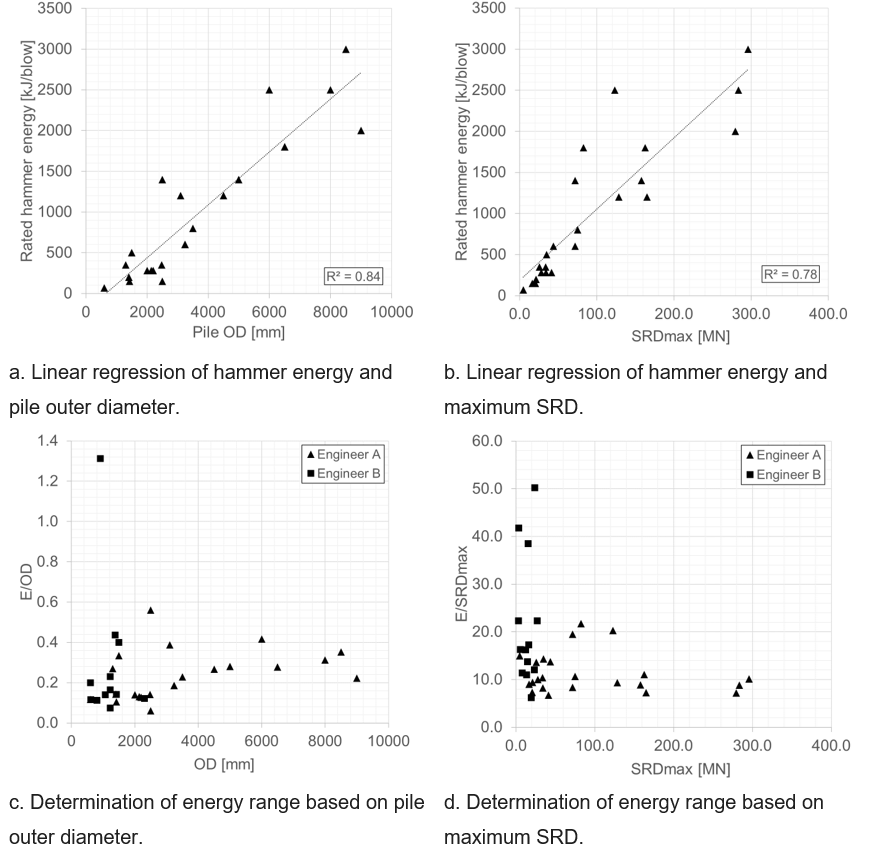
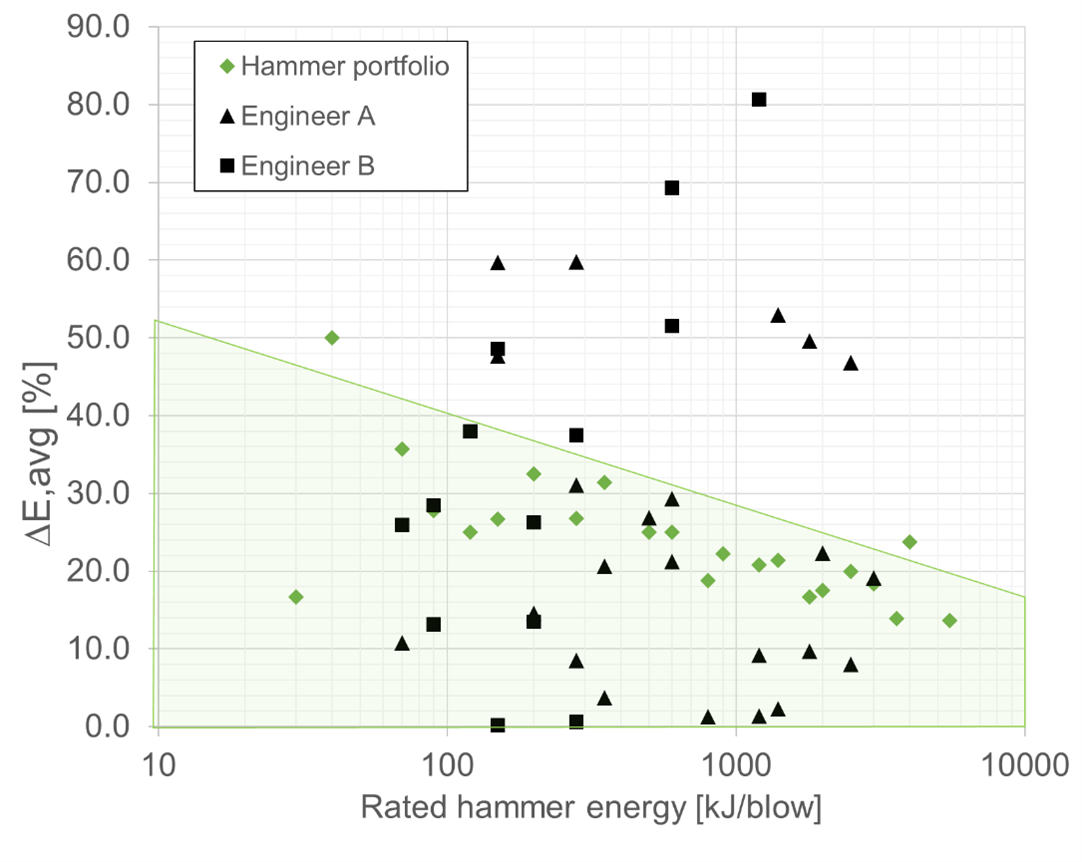
To arrive at a preferred model confidence interval, we have looked at the average relative energy step size in the IQIP hammer portfolio, which shows the relative difference in hammer rated energy when going from one hammer to the nearest option in the portfolio. In Figure 3 we show the relative difference in energy between two successive hammers in the IQIP portfolio together with the relative energy range based on Figures 2c and 2d. With the simple ML model of example 1, we were able to predict ~70% of the projects already within the established confidence interval, see the green polygon in Figure 3
For the second example, we looked at the machine-learning challenge organized by the ISFOG in 2020 (ISFOG, 2020). Figure 4 shows the correlation matrix of the available parameters, and the parameters with best correlations with the envisaged output are the best candidates for including in modelling. In the ISFOG challenge, the blowcount and final number of blows for certain pile driving projects needed to be predicted based on a training dataset of 94 records. IQIP did not participate in the challenge in 2020, however for the purpose of this paper we applied a 4-layer neural network (deep learning) algorithm to the dataset (details in Figure 5). We were able to reach a coefficient of determination R2=0.95 in predicting the total number of blows and R2 = 0.82 in predicting the blowcount (see Figure 6), from which we can conclude that based on a rich dataset, one can have solid predictions of important parameters of the pile driving process.
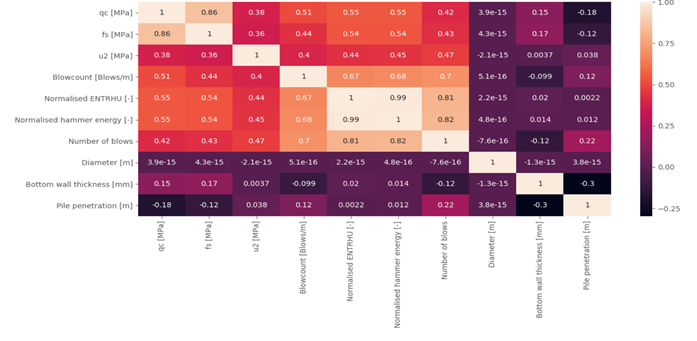
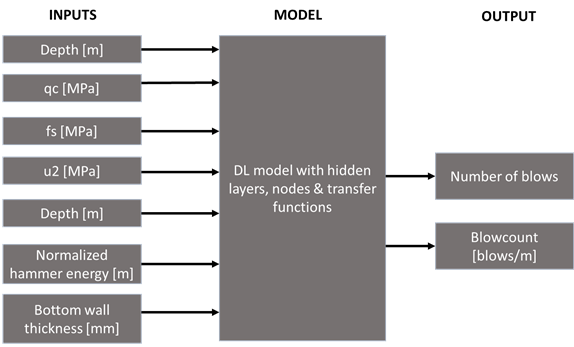
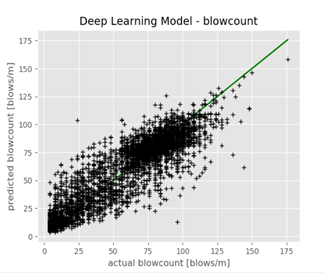
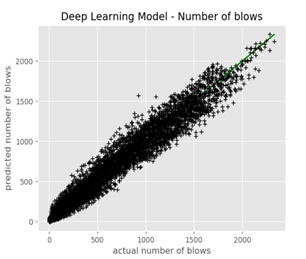
Figure 6. Prediction of the number of blows at final penetration (left pane, R2 = 0.95) and blowcount (right pane, R2 = 0.82) using the deep learning model on the ISFOG dataset.
RISK REDUCTION: DATA VALORISATION IN EVERY STAGE OF A PROJECT
The promise of risk reduction with data science techniques in foundation installation lies in well-informed decision making in every stage of the project. This requires new products and services that deliver this value to customers. Two of the innovations IQIP envisages are geotechnical advice for foundation installation in an online portal and real-time, on-site updates of pile driving procedures.
Carrying out driveability analyses during the early stages of a project is beneficial for the as one can validate the feasibility of the project, accuracy of the engineering design and have a rough indication of equipment costs. Machine learning algorithms are only valid within the range of data used to train the algorithm, hence early stage calculations are only possible for regions for which sufficient historical data is available. These data can be driving records or regular predictions of previous projects.
IQIP intends to offer its customers access to data services via the an online portal. Via this digital portal customers could request preliminary geotechnical advice for foundation installation. By uploading CPT data and pile design data customers can receive preliminary advice on hammer selection and driveability in a matter of hours. Utilizing the technology hosted in the data hub and expert verification, the customer receives feedback on the delivered data based on cross checking other projects with similar CPT and pile designs in the data hub.
The cross check in the data hub allows for categorizing the foundation installation project in different risk categories: Low Risk (e.g. many similar projects looking at hammer type, system configuration, pile design and soil conditions), Medium Risk (e.g. potentially difficult circumstances, few references available, rare soil conditions) and High Risk (e.g. known geohazards, history of pile run in similar projects, known high noise emissions).
On project execution level, IQIP envisages real time pile driving instructions for every new pile as an option for complex, high risk projects. Contrary to the initial stage design, which requires data with a global coverage and aims for checking feasibility of a project, the actual project execution phase demands precise and very local information of the pile driving operation. For instance, when installing an offshore windfarm, every newly installed pile in the project gives direct feedback about soil conditions and equipment performance. When fed back in the data hub, the piling procedures for the specific project could be updated and uploaded to the hammer control unit. In this way the operator will get the best-informed piling instructions possible for every new pile, which can for instance help in reducing the risk of pile run to a minimum or help in adhering to noise regulations.
CONCLUSIONS
As projects increase in size and complexity, project risks increase as well. In order to reduce risks, it is important to be able to learn from past experience. IQIP aims to turn its long track record of foundation installation projects into customer value by using machine learning and incorporating data driven services in its portfolio.
Current driveability analyses incorporate learning by project back analysis, aimed at improving SRD models, which only partially capture the lessons from previous projects. Machine learning is well suited for multivariable, non-linear relations. These are prevalent in foundation installation projects due to the nature of the hammer-pile-soil interaction. ML algorithms are able to incorporate all relevant historical data into every new project without the need for intermediate physical modelling and without being limited to one or a few parameters (often the SRD) only.
The quality of ML predictions is fully governed by the quality and quantity of the available data as it does not (necessarily) include physical relations between parameters. IQIP has explored deep learning (neural network) algorithms and more conventional regression and data-clustering methods for the purpose of predicting the number of blows, the blowcount and hammer selection, with encouraging results. With the methods in place, more advanced applications can be investigated.
IQIP is developing data services to assist clients in different phases of their projects, incorporating a data hub and machine learning. One example is preliminary equipment advice via an online portal, for equipment selection in an early stage of the project without the need for a driveability analysis (however with the option for follow-up with an extensive analysis by an expert). Another is cross-checking of projects with similar projects in the data-hub to give a risk classification, providing an indication of mitigation measures to be taken.
IQIP envisages risk reduction on project execution level by offering real-time updates of piling procedures based on previously installed piles, which is especially useful in larger projects. The updated procedure for the next pile could be made available to the operator via the hammer control system.
REFERENCES
Alvarez Grima, M. (2000). Neuro-Fuzzy Modeling in Engineering Geology: Applications to mechanical rock excavation, rock strength estimation, and geological mapping. PhD thesis, Delft University of Technology
ISFOG (2020). ISFOG 2020 Data science prediction event – dataset https://www.kaggle.com/c/isfog2020-pile-driving-predictions/data, retrieved June 2021.
